疫情下的炼丹笔记(yolov3计算map)🎈
本文最后更新于:2022年3月3日 下午
前言
好久没写,最近发生的事情太多了,简要汇总下吧。12月22日,西安要封城的消息传遍了VX群,随即收拾资料准备居家办公做好持久战的准备。短短一周防疫政策的不断变化让很多物资储备不足的小伙伴慌了起来,当时去屯物资的时候还在疑惑,怎么大爷大妈扛着整袋面粉,盐也要买好几袋。“ 菜量充足,不必哄抢。一键下单,送到你家。” 这有问题吗?没有啊!有问题的是老实人你。。 只能说大爷大妈的预判YYDS。
后来嘛,就是居家封闭,定期核酸检测。醒来第一件事就是查看核酸检测结果,看着每天新增的病例数,每个人都期盼着拐点的出现。ww没想到去年屯的五谷派上了用场,还好在家学会了几道菜,这三板斧解决吃饭难题。因为这波疫情,整天被圈在个水泥盒子里的人也被联系了起来。夜深人静,群里谈及梦想,都挺不容易。“都睡了几天了 该有不该有的梦里都有了 就是没能走出这个房子”,焯!彩票梦,老板梦的气泡一个个的被扎破。生活嘛,总是让一批又一批不知死活的小b崽子在不知不觉中成长,耳机里又响起 “想学功夫 修炼仙术 先征服这条山路 我在三清观里录歌 旋律和韵脚兼顾” 《崂山道士》—Masiwei。

新年了,新年了。被关在这里,只能用一场酩酊大醉送走2021,从炸金花玩到摇骰子,到最后的真心话大冒险。新的一年,只希望自己平安喜乐,一切都尽快的回归正轨。一周多了,睡也睡够了玩也玩够了,是时候充实自己了。古有“天大寒,砚冰坚,手指不可屈伸,弗之怠”,每想到这句诗就找不到不学习的理由。
接着之前的工作,初识YOLO算法后对采集的数据进行处理。这段时间的规划是:制作数据集、训练模型、模型优化。这次的数据训练是在Windows下采用YOLOV3训练自己的数据,达到对目标的较高可靠度的准确识别。
制作数据集
使用labelimg标注工具,对图片中感兴趣的目标进行标注,为后续的训练提供目标信息在图片中的信息,其中主要包括类别信息以及位置信息:两个点坐标(xmin,ymin)(xmax,ymax)

低对比度小目标识别检测:上图目标像素大小大概为371 X 240 ,原图片像素为2000w像素:5472 X 3648)
①labelimg标注后生成对应的xml文件
②使用python脚本将位置信息转换为YOLO训练所需要的数据格式,生成对应的txt文件。最后将图片与txt文件都放输入data\obj目录下,方便后续使用。
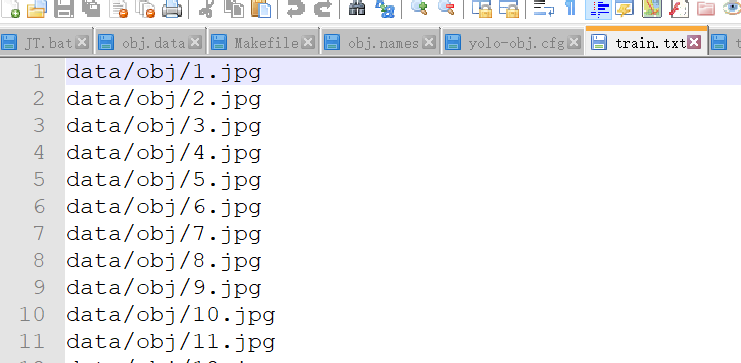
③新建一个类别文件obj.names (内容只需要填写自己的类别名称,中文名称需要做数据集是中文标签,且在源代码中修改相关文件并重新编译), 新建一个图片目录文件train.txt, 都放到data/目录下
总的来说,训练的时候会用到obj.data文件。而obj.data写入了train.txt以及obj.names,train.txt又写入了标注好的图片路径,从而达到一连串的调用。
训练模型
准备工作:
①在修改训练轮次 max_batches = 8000,按照以往经验200张左右的图片,训练8000轮就够了
②Windows版的darknet-YOLOV3提供了map命令,可以一边训练数据集一边计算训练集的map以寻找最优模型。
命令如下:
1 | |
报错记录:错误信息说的是obj.data里的test.txt没有对应的测试数据
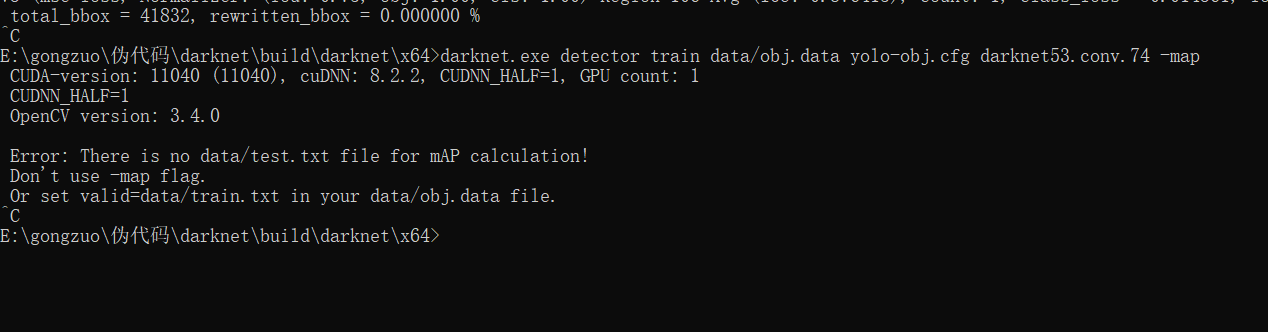
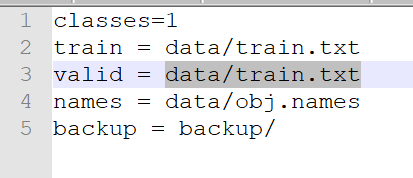
valid = data/test.txt 改为 valid = data/train.txt
开始训练:
这次使用map命令边训练边计算 average perscion,如红线所示,极其不稳定。
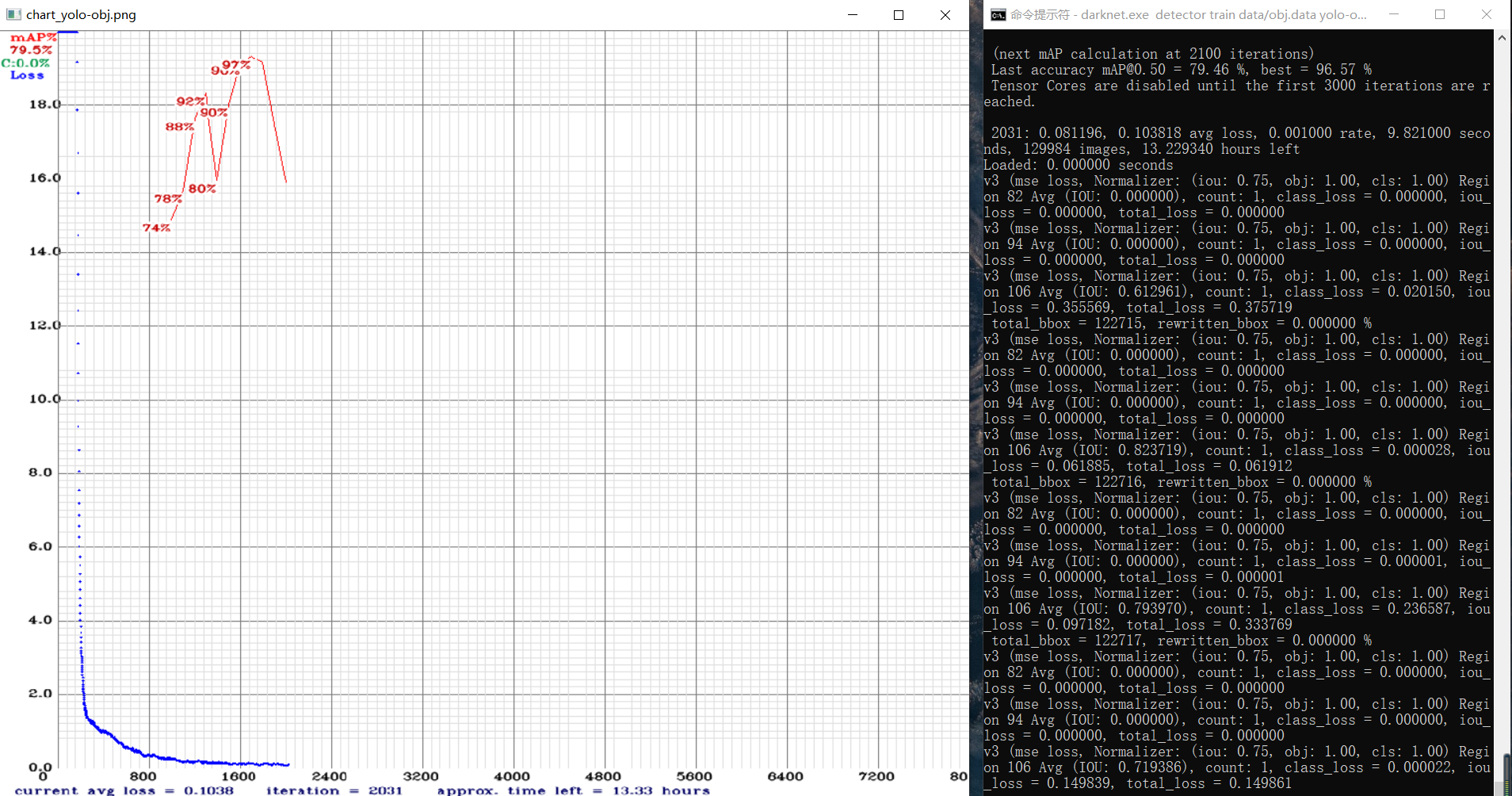
群里问了下出现这种情况有两种可能:训练的数据太少了(确实少),batchsize设置的较小(有待研究)
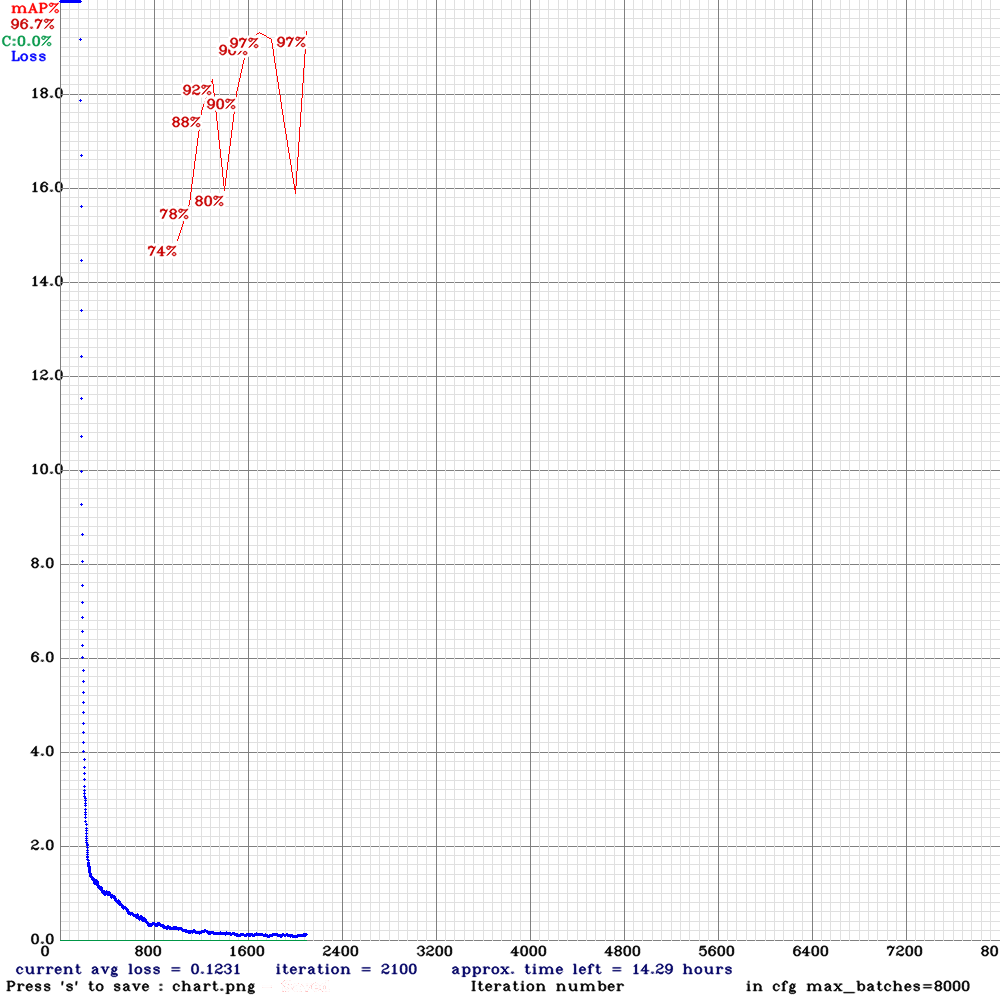
这个时候停止训练,计算一下测试集的mAP。
测试集的mAP计算
①标注测试集对应的目标信息,和训练集一样用labelimg生成xml文件,转换为txt文件。
②新建test.txt,和train.txt一样写入待测试图片的路径,通过调用obj.data里的valid = data/test.txt实现对测试图片的调用。
③测试命令如下:
1 | |
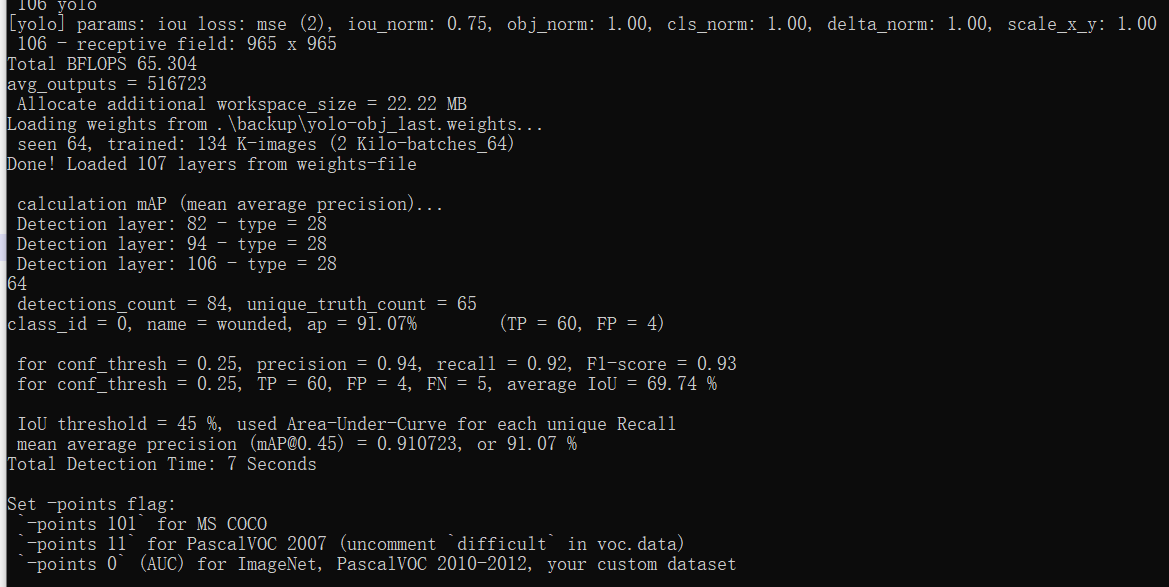
测试结果表明:mAP(只有一个类别所以平均准确率AP = mAP) 达到惊人的91.07%
其中,测试结果参数解析:
1 | |
测试效果
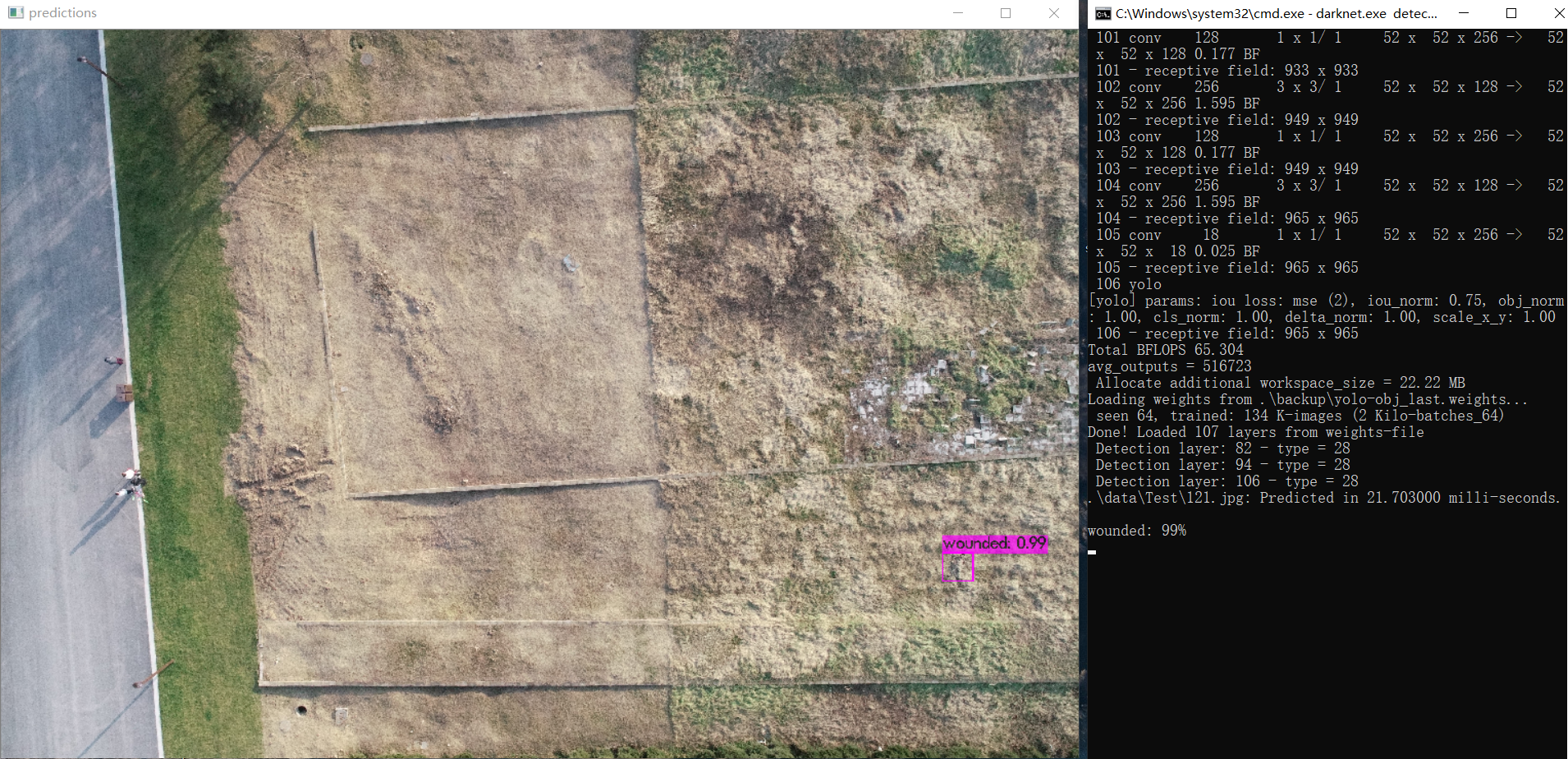
图片检测:
测试集里随便拉一张图片,执行如下命令,看下效果。
1 | |
视频检测:
错误记录:video stream stopped ,大部分是缺少openCV相关文件。复制·openCV安装目录下的opencv_ffmpeg340_64.dll文件到darknet\x64目录下,问题解决。
执行如下命令:
1 | |
总结
深度学习,道阻且长。革命尚未成功,同志仍需努力!
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!